
Si tienes una web seguramente alguna vez te has preguntado que hace Google para posicionarla. Aunque un buen consultor seo lo tiene claro, no es algo trivial y en muchas ocasiones no se conoce el proceso seguido.
En este artículo te explicamos los pasos que sigue: rastreo, indexación y posicionamiento
Comprende cómo los motores de búsqueda rastrean e indexan tu web
El SEO es el proceso de optimizar las páginas de una web para lograr aparecer en las primeras posiciones de las SERPS ( resultados de búsqueda ). Para ello, lo primero que tiene que hacer un buscador como Google es saber que existe esta página y que contiene, es decir «rastrearla», y después ponerla en su índice de páginas a mostrar, lo que equivale a «indexarla». El último paso será darle una «valoración» para mostrarla en una u otra posición según la búsqueda realizada por el usuario, es decir “posicionarla”
Veamos cómo es el proceso de rastreo e indexación y que podemos hacer para que sea lo más rápido posible.
¿Qué es el rastreo de una web?
Para explicarlo de manera simple, el rastreo es el proceso que realizan los motores de búsqueda con rastreadores web, también llamados bots o arañas, para encontrar nuevas webs, nuevas páginas de webs ya existentes o bien para revisar si las ulrs ya descubiertas han sufrido algún cambio, tienen enlaces rotos, etc.
Cuando las arañas visitan cualquier sitio web, siguen los enlaces internos para ir descubriendo y rastrear otras urls de la misma web o bien de otras webs si hay un link que apunta a ella.
En otras palabras, cada vez que la araña rastrea las páginas web, pasa por el DOM (Document Object Model) que representa la estructura de árbol lógica del sitio web.
Técnicamente hablando, DOM es el código JavaScript y HTML renderizado de las páginas del sitio web.
Un bot al rastrear una web no la rastrea toda a la vez, sino que rastrean las partes más importantes de la web que son importantes para ayudar a clasificarla. Cada cierto tiempo, dependiendo de la importancia que da el buscador a la web, la araña volverá para seguir rastreando.
Para facilitar el rastreo es importante crear un o varios ficheros llamados sitemaps, donde se incluyen una lista de las urls de la web. Para facilitar a Google como encontrar estos ficheros podemos indicárselos en Google Search Console en el apartado Sitemaps.
Cómo optimizar la web para el rastreo de Google
Para facilitar el rastreo es importante crear un o varios ficheros llamados sitemaps, donde se incluyen una lista de las urls de la web. Para facilitar a Google como encontrar estos ficheros podemos indicárselos en Google Search Console en el apartado Sitemaps. Mira este enlace para ver que nos dice Google sobre los Sitemaps
El Google Search Console se puede verificar para cada uno de los sitemaps que se hayan indicado cuales urls están ya indexadas, cuales están rastreadas pero pendientes de indexar, si algunas presentar errores de rastreo o bien han sido excluidas por algún motivo.
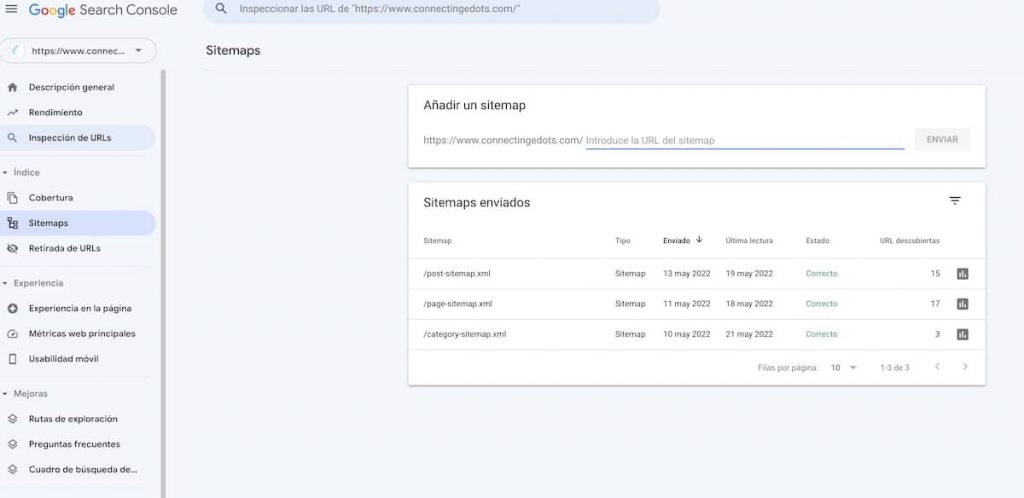
Una buena práctica es generar un sitemap para cada uno de los segmentos que tengamos en la web ( servicios, blog, categorías, etc), de esta manera podemos verificar si una parte de la web se está rastreando y/o indexando mejor que otras y tomas acciones correctivas en caso de que haga falta.
En general no queremos que Google rastree todas las partes de la web, algunas porque no son importantes, otras porqué contienen contenido que no tiene sentido indexar, etc. Esto es especialmente importante si tenemos en cuenta que las arañas sólo dedican un tiempo al rastreo de nuestra web, por tanto, nos interesa que el rastreo se concentre en las secciones importantes y no se pierda tiempo en otras. El tiempo que nos tiene asignado Google para el rastreo se conoce como el «crawl budget» ( traducido sería «presupuesto de rastreo»).
Para indicar a los bots qué contenido se puede rastrear y cúal no se utiliza el fichero «robots.txt» que se debe colocar en la raíz de nuestra web ( https://miweb.com/robots.txt ). En este fichero con las directivas «Allow» y «Disallow» indicaremos que secciones son rastreables y cuales no, también se puede indicar para cuales arañas es rastreable o no una parte o la totalidad de la web.
Elementos clave que afectan el rastreo de una web
Una araña no rastreará el contenido de las páginas que sólo son accesibles si el usuario ha iniciado sesión en la web ya que el bot no puede iniciar sesión.
Los bots tampoco rastrean la información que aparece después de realizar una búsqueda desde el buscador interno de la web. Esto hay que tenerlo especialmente en cuenta para las webs de comercio electrónico.
Tampoco está garantizado que el bot rastree elementos multimedia como audio, videos e imágenes. Por lo tanto, se recomienda agregar las metaetiquetas HTML como el «alt» y «description» de las imágenes para ayudar a la araña a interpretar la información que muestra la web.
Cuidado con abusar de Javascript. Hasta hace unos años los bots como Googlebot, no rastreaban ni indexaban el contenido generado dinámicamente con JavaScript y sólo rastreaban código HTML.
Actualmente Google puede rastrear e indexar la mayoría del contenido generado con JavaScript, aún así recomienda usar la representación del lado del servidor, en lugar de hacerlo del lado del cliente. En general a los boots de Google les costará más rastrear una página generada con JavaScript que con HTML y por tanto se «gastará más crawl budget» para ello.
Para que una página pueda ser rastreada debe ser accesible a partir de algún enlace que haya descubierto la araña, y cuanto menor sea el nivel de profundidad ( clicks necesarios desde la home para llegar a la página ) más fácil será que sea rastreada, de ahí la importancia de tener un buen enlazado interno.
Las páginas que no tienen asignados enlaces internos se conocen como «Páginas huérfanas» y, por lo tanto, permanecen casi invisibles para las arañas mientras rastrean el sitio web.
Otra factor a evitar son los errores de rastreo, como son los 404 o 500. Si un bot al rastrear una web encuentra muchas url que retornan un código de respuesta 404 o 500 seguramente dejarán de rastrear la web, al considerarla de poca calidad y con errores. Por lo tanto, se recomienda redirigir las urls que ya no existen, al haberlas cambiado o borrado por haber generado un nuevo contenido que las engloba, con un redireccionamiento temporal ( código 302 ) o un redireccionamiento permanente (código 301).
En algunos casos, como por ejemplo la url de un producto de un ecommerce que ya ha dejado de fabricarse y no se volverá a fabricar, si se puede dejar el 404. Pero este tipo de errores nunca deben ser un número significativo comparado con el número total de urls de la web.
¿Qué es la indexación de una web?
Ahora que sabemos qué es el rastreo, veamos que significado indexar una web.
Podemos definir la indexación de una url como el proceso de archivar la información recopilada en la fase de rastreo en la base de datos del índice de búsqueda, mediante el cual los datos indexados se comparan con los datos almacenados previamente con métricas y complejos algoritmos SEO con páginas similares, lo que ayuda al proceso de clasificación de una web por parte de los motores de búsqueda.
¿Cómo podemos saber si Google ha indexado nuestra web?
Hay varias maneras de comprobar si una url de una web está indexada, la más fácil es utilizar el comando «site» desde un navegador.
Simplemente escribiendo «sitio:dominio_de_la_web» y Google nos retornará las urls que tiene indexadas del dominio especificado. Si se quiere saber si una url concreta está indexada se puede utilizar el comando site con la url concreta «site:dominio_de_la_web/resto_url»
Otra manera de saber el estado de indexación de una url es revisar el apartado «Cobertura» en Google Search Console (GSC), o bien la «Inspección de urls», también en GSC.
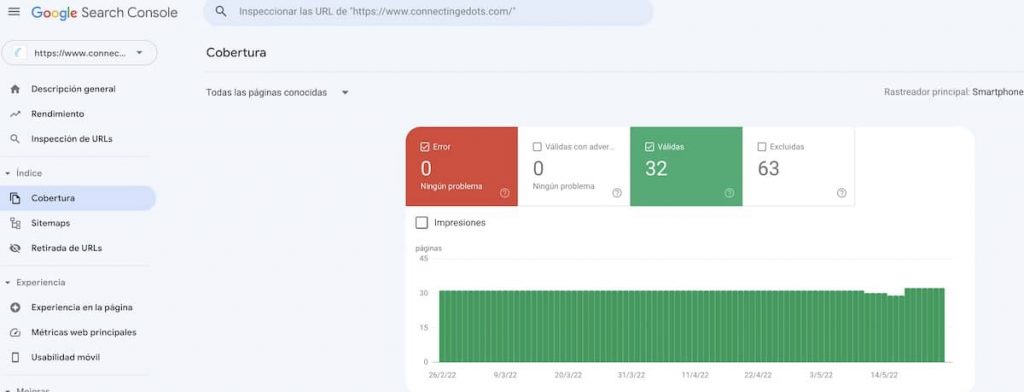
La indexación de las urls de una web es un requisito previo a que estas puedan aparecer en los resultados de búsqueda, por lo que es vital que si queremos que Google las tenga en cuenta en las SERPS, estas urls puedan ser rastreadas para luego ser indexadas.
Esto significa que si el contenido no es visible para el bot de Google, la página no será indexable y por tanto no aparecerá en SERPS.
Cuando se realiza la indexación, el rastreador cataloga la página en el índice de Google, la base de datos de la Búsqueda de Google. Actualmente el índice de Google cuenta con cientos de miles de millones de páginas web.
Una vez que una página o url está indexada, está lista para ser mostrada en las SERPS dependiendo de las búsquedas realizadas por el usuario.
Posicionamiento: cuando Google recibe una consulta, ¿como decide que resultados mostrar?
Una vez que una url está indexada el buscador de Google ya puede decidir en qué posición mostrarla según la consulta realizada.
Cada vez que un usuario hace una consulta en el buscador, Google recurre a su índice para encontrar y mostrar aquellas urls que considera más relevantes para satisfacer la intención de búsqueda del usuario.
Veamos cómo decide Google que resultados mostrar ante una búsqueda
Definición del contexto y filtrado del índice
En el momento en que se envía una solicitud de búsqueda, Google ya tendrá en cuenta algunas factores que lo ayudarán a reducir el índice y filtrar los resultados irrelevantes. De entre estos factores destacaríamos la ubicación, el idioma, el tipo de dispositivo y la configuración de búsqueda del usuario.
Identificar la intención de búsqueda.
Una vez que Google recibido una solicitud de búsqueda, debe comprender el significado real detrás de la consulta.
Lo primero que hace Google es reconocer nuevas palabras y corregir errores ortográficos utilizando modelos de comprensión del lenguaje natural. A partir de ahí, Google identifica el significado y la intención de búsqueda del usuario.
Para identificar la intención de búsqueda Google utiliza Inteligencia Artificial, principalmente 3 sistemas de procesamiento semántico: RankBrain , Neural Matching y BERT .
Al aplicar estos tres algoritmos de IA, Google comprende el significado de la consulta y pasa a la siguiente etapa.
Clasificar el tipo de consulta
Google determinará el tipo de consulta que ha hecho el usuario. Por ejemplo si se trata de una consulta que requiere contenido reciente, ahí aplica el modelo matemático Query Deserves Freshness (QDF), o bien si la consulta es referente a temas sensibles relacionados con «Your Money Your Life» (YMYL) ya que estos últimos requieren respuestas desde webs con un alto EAT (Experiencia, Autoridad y Fiabilidad)
Definición del formato de las SERP
Dependiendo del tipo de consulta el formato de los resultados de búsqueda ser diferente. Por ejemplo, junto con los diez ( a vece s menos) enlaces de la primera página, se puede mostrar anuncios, resultados de Knowledge Graph, un mapa, etc.
Entonces, antes de que Google devuelva su SERP final, decide qué tipo de resultados de búsqueda serán los más adecuados.
También hay una diferencia notable entre cómo Google elige qué bloques SERP mostrar según el tipo de dispositivo desde el que se ha realizado la búsqueda ( básicamnete desde móvil o desde desktop)
Selección de las páginas más relevantes para cada tipo de bloque a mostrar en las SERPS
A partir de los puntos anteriores Google decide que resultados mostrar en cada uno de los bloques según el formato de la SERP. Para evaluar la relevancia del contenido, Google analiza el texto, las imágenes, los videos, así como todos los metaelementos, como el título, la metadescripción y las etiquetas alternativas.
Aquellas páginas que sean más relevantes, es decir, que cumplan mejor con los requisitos del usuario, obtendrán una clasificación más alta. Dicho esto, debes recordar que la relevancia del contenido, aunque vital, no es el único factor de clasificación. Es la combinación de muchos factores lo que acaba definiendo una buena posición en los resultados de búsqueda.
Relevancia e importancia de las páginas
Google clasifica las páginas priorizando el contenido más confiable y de calidad. De hecho, trata de lograr el equilibrio adecuado entre la relevancia y la autoridad de la información en esta etapa.
Para este fin Google evalúa la calidad del contenido de la página y la experiencia del usuario
Obviamente, las páginas que brindan calidad y facilidad de uso tienden a clasificarse más alto en los resultados de búsqueda.
Devolver los resultado de búsqueda
Cuando la consulta se ha analiza desde todos los ángulos y los algoritmos de IA han hecho su trabajo, Google finalmente devuelve los resultados de búsqueda más relevantes
Conclusiones
Si quieres que una url se posicione bien para unas búsquedas en Google, debes tener contenido relevante, pero no es menos importante facilitar el rastreo y la indexación a los boots de Google.
Necesitas ayuda en ello, contáctanos sin compromiso.
Licenciado en Informática por la UAB.
Después de 25 años como director del departamento de desarrollo en Limit Tecnologies fundé mi propia agencia Connectingedots en 2012 desde dónde gestionamos proyectos relacionados con:
-SEO, SEM Y CRO
-Campañas de Google Ads ( Certificación en Google Ads)
-Analítica WEB
-Visualización de datos
Formación continua para estar a la vanguardia del marketing Digital
Puedes acceder a más información en mi perfil de linkedin:
https://www.linkedin.com/in/felip-mas-sureda-41245331/
o en Twitter https://twitter.com/felip_mas
Master en SEO AVANZADO por Webpositer
Master en Analítica por Webpositer e Ikaue
Master en CRO por Webpositer


